
本文记录一下我在2020华为云大数据挑战赛的热身赛阶段部分比赛过程、经验以及遇到的问题。
赛题回顾
竞赛链接:https://competition.huaweicloud.com/information/1000037843/introduction
简单解读
利用历史数据并结合地图信息,预测深圳市五和张衡交叉路口未来一周周一(2019年2月11日)和周四(2019年2月14日)两天的5:00-21:00通过wuhe_zhangheng路口4个方向的车流量总和。
所给的数据集不大,数据处理起来比较棘手,要预测的日期还是两个比较特殊的日期(春节后第一天上班和情人节)。整体不太好下手。
评分标准
赛题给出了两个评分标准(具体解释见赛题),一个是分类问题:
另一个是回归问题:
分析一下分数标准的两部分,分类问题是依靠每个区间的数量的大小来判断得分,回归问题主要依靠每一个区间的误差来判别,就算最终提交的答案所有区间都为同一个数(0除外),最终得分应该也有30左右。也就是随便输出一个结果,最终得分就可以30+。
数据分析
对所有数据(有缺失的数除外)做可视化,结果如下(建议右键单独打开图片):
可以看到数据集中有很多离群值,通过对图片的观察,去除离群数据,再结合历史数据猜想春节后第一天上班和情人节两天可能的流量趋势,2-11因为是第一天上班,所以流量应该不是很大,2-14是情人节,但是是工作日,所以晚上车流量应该比较大。在做题过程中我筛选出了两组数据,做了一个简单的可视化:
第一组
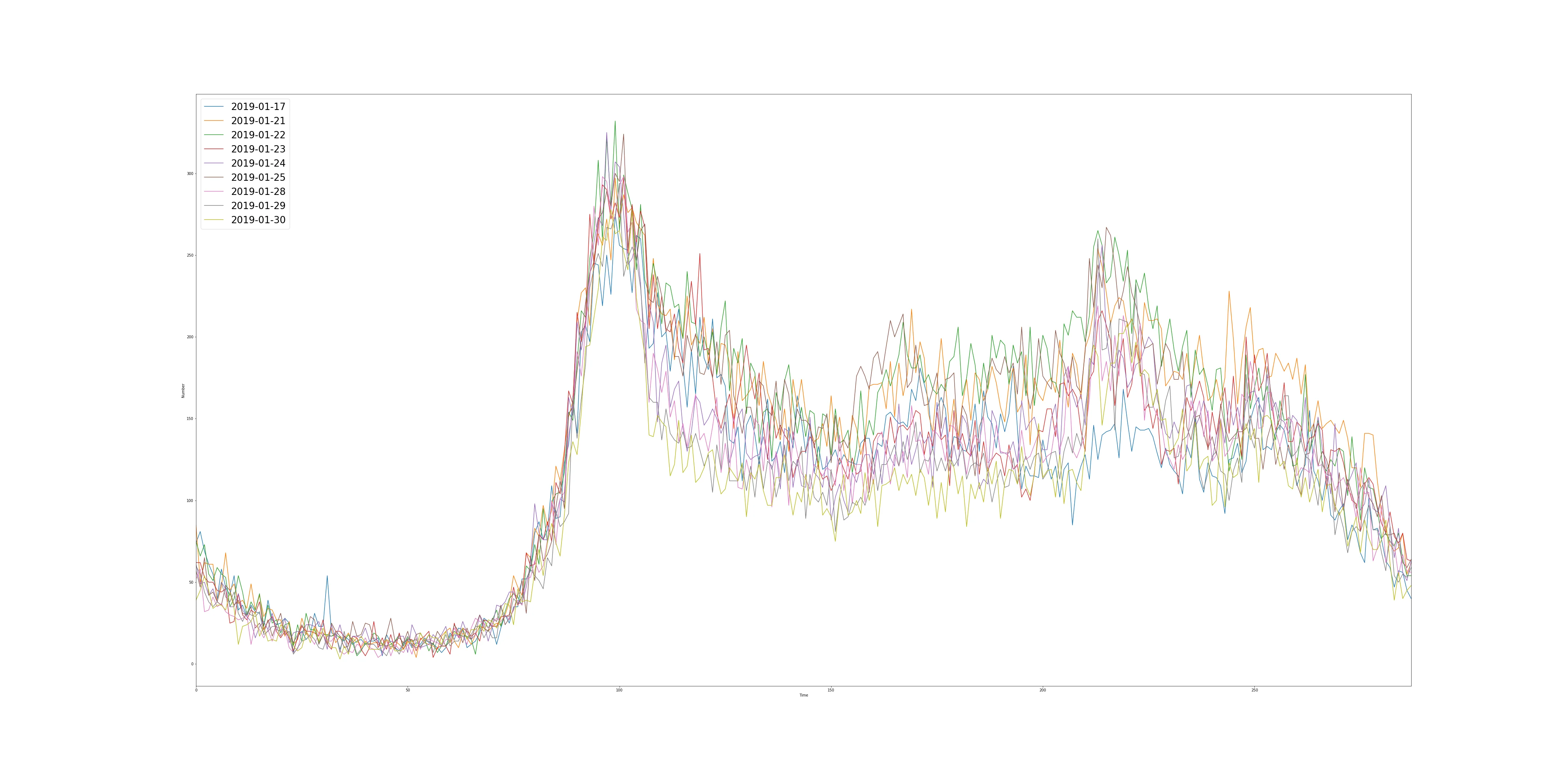
第二组
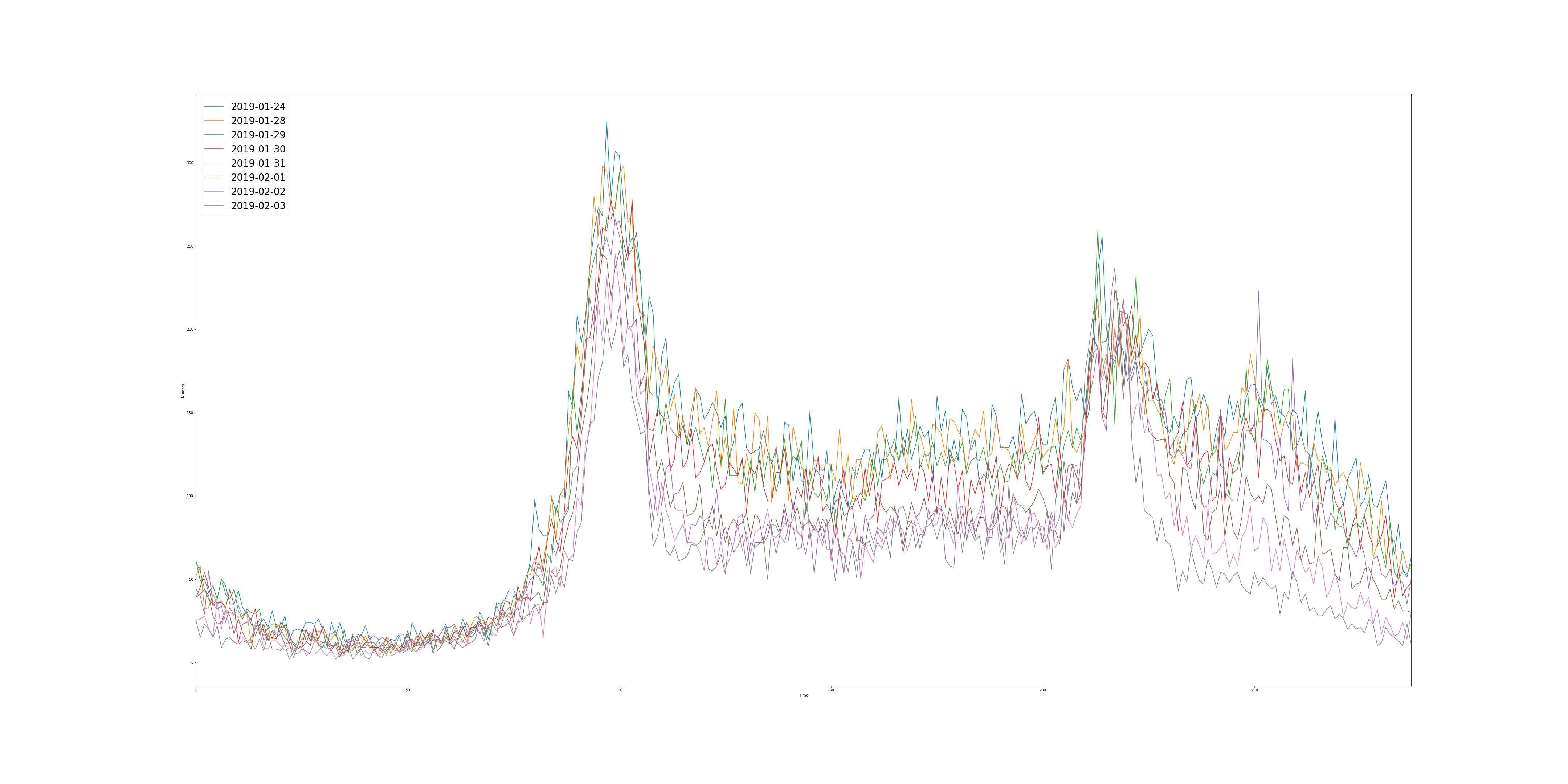
预测模型
v0.0.1-Baseline
这个是官方给出的参考模型,方法如下:
数据集:全部数据
1. 将所有数据中五和张衡路口的数据都读进来
2. 对每一个时间段,五和张衡路口各个方向的车流量做平均聚合
3. 提取日期特征,将日期用星期几来表示,比如星期一就用0,星期日就用6,然后归一化约束成[0, 1]的一个小数
4. 将时间做一个归一化,约束成[0, 1]的一个小数
score:35.6483很明显,官方给的参考只是一个参考而已,方法是错的,题目要求预测四个路口车流量总和,而baseline里却对数据做了平均,虽然方法是错的,不过也证实了我一开始对评分标准的大胆猜想(随便提交一组数据得分就可以30+)。
v0.0.2-基于baseline的修改
数据集:全部数据
1. 将所有数据中五和张衡路口的数据都读进来
2. 对每一个时间段,五和张衡路口各个方向的车流量做求和聚合
3. 提取日期特征,将日期用星期几来表示,比如星期一就用0,星期日就用6,然后归一化约束成[0, 1]的一个小数
4. 将时间做一个归一化,约束成[0, 1]的一个小数
score:40多(提交次数太多+时间久远,忘了具体是哪个了)只是简单修改了一下,分数就有一个较大的提升。
v0.0.3-基于XGBoost的模型
XGBoost是一位大佬在打Kaggle竞赛时提出的一个方法,之后一直被广泛应用于各类数据科学竞赛,其原理为:https://www.bilibili.com/video/BV1S441147Ae。在baselin原有特征的基础上,我又引入了天气、节假日两个特征,具体如下:
数据集:全部数据
1. 将所有数据中五和张衡路口的数据都读进来
2. 对每一个时间段,五和张衡路口各个方向的车流量做求和聚合
3. 提取日期特征,将日期用星期几来表示,比如星期一就用0,星期日就用6
4. 将时间用分钟表示
5. 使用爬虫爬取的天气数据,参考【2017天池口碑商家客流量预测】的天气特征数据提取天气特征
6. 添加节假日特征,如果是节假日(含周末)值为1,不是值为0
score:56.7203使用XGBoost并添加了两个特征之后,得分又有大幅提高。
v0.0.4-参考时间序列预测做特征工程
在做完数据可视化之后,很明显车流量与时间有关,具有一定的周期性,于是想到了时间序列预测,使用LSTM做时间序列预测效果时很好的,但我对于LSTM的理解不是很深,没有使用它,但受时间序列预测启发,提取了新的特征。
时间序列预测是根据历史数据,预测未来数据,即输入为已有的数据,输出为未来的数据。
时间序列预测输入中包含历史数据,直接将历史数据作为一个特征引入显然不太合理,于是我对历史数据取均值、中位数、最大值、最小值作为特征引入,最终结果和预期的一样,有较大提升。
具体方法:
数据集:第一组
1. 将所有数据中五和张衡路口的数据都读进来
2. 对每一个时间段,五和张衡路口各个方向的车流量做求和聚合
3. 提取日期特征,将日期用星期几来表示,比如星期一就用0,星期日就用6
4. 将时间用分钟表示
5. 使用爬虫爬取的天气数据,参考【2017天池口碑商家客流量预测】的天气特征数据提取天气特征
6. 添加节假日特征,如果是节假日(含周末)值为1,不是值为0
7. 引入历史数据的均值、中位数、最大值、最小值
score:68.6139v0.0.5-去掉天气特征
经过绘制特征重要性直方图,发现天气这个特征对于模型的贡献很小,于是萌生了删除这个特征试试的想法。删除后得分有一点提升,得分为68.6973,说明天气这个特征属于噪声,简单分析了原因,我的猜测如下:
要预测的数据时间粒度很细(每5分钟),而爬取到的天气数据是以天为单位,时间跨度相差太大,所以引入天气并不能达到提高精度的效果,除非有每小时的天气数据。
后续弃用了天气这个特征
v0.0.6-均值预测
历史数据在一定程度上可以反应未来趋势,所以我做了一个大胆尝试,直接对历史数据取均值,然后提交评测,由于需要使用华为云的一站式AI平台(ModelArt),所以我的方法如下:
数据集:第一组
1. 将所有数据中五和张衡路口的数据都读进来
2. 对每一个时间段,五和张衡路口各个方向的车流量做求和聚合
3. 对数据求平均值
4. 使用pickle保存数据
5. 随便找个模型进行构建,覆写推理代码中负责推理的部分,直接在这里取得数据文件的路径、读取数据并return数据
score:70.0869本来没报什么希望,但没想到的是,这个方法居然可以有70多分。
v0.0.7-使用另一组数据集
之前使用的是全部数据、第一组数据,接下来尝试的是第二组数据集
数据集:第二组
1. 将所有数据中五和张衡路口的数据都读进来
2. 对每一个时间段,五和张衡路口各个方向的车流量做求和聚合
3. 提取日期特征,将日期用星期几来表示,比如星期一就用0,星期日就用6
4. 将时间用分钟表示
6. 添加节假日特征,如果是节假日(含周末)值为1,不是值为0
7. 引入历史数据的均值、中位数、最大值、最小值
score:70.4581得分有小幅度提升
v0.0.8-两组数据集结合的均值预测
根据上一版本得到的数据图像来看,2-11的数据和第二组数据趋势相似,2-14的数据和第一组数据相似,于是取第一组数据的均值作为2-14的结果,第二组数据的均值作为2-11的结果,得分又有提升,得分:73.5446
v0.1.0-基于XGBoost、LightGBM的融合模型
受随机森立等分类器的启发(随机森林是多个决策树的融合),多个弱分类器组装在一起,得到的是一个强分类器,所以一个有点奇葩的想法出现在我的脑海中——训练多个模型,然后将几个模型所得的将结果按权重求和。
数据集:第二组
1. 将所有数据中五和张衡路口的数据都读进来
2. 对每一个时间段,五和张衡路口各个方向的车流量做求和聚合
3. 提取日期特征,将日期用星期几来表示,比如星期一就用0,星期日就用6
4. 将时间用分钟表示
6. 添加节假日特征,如果是节假日(含周末)值为1,不是值为0
7. 引入历史数据的均值、中位数、最大值、最小值
8. 分别训练不同的模型,得到多组预测值
9. 按权重将多组预测值求和,得到最终结果
score:72.8234最后结果虽然相比上一个版本低了一些,但这个版本还有很大的提升空间。
v0.1.1-融合模型+均值预测
在上一版本的基础上,对预测结果进行操作,即将融合模型的预测结果和v0.0.8的结果取均值,最后得分再次提升,得分为:74.9557
其他版本
竞赛尚未结束,暂不记录,害怕被主办方爸爸看到,受到制裁
总结
尝试不同方法的过程中,分数并不是一帆风顺一直提高到,而是忽高忽低,甚至两次提交有十几分得差距,上述内容没有记录一些有负优化的尝试,所以看起来得分是一路上升,只有不断去尝试,不断去试错才有可能将分数一步步提高。
后续
昨天在竞赛官方群里,很多人在组队,有清华的研究生大佬,有请到了Google外援的大佬,华友MIT的PhD大佬,大佬们已经开始抱团,月底偷塔了,难以想象正式赛的排行榜画面,我一个菜鸡就看看神仙打架,凑凑分母就好了
目前没有什么思路了,排名已经连续下降,只希望现在的排名可以坚持住
结果
最后几天没抱啥希望,把三个模型的结果平均了一下,没想到出现了惊人的效果,最后排名第三。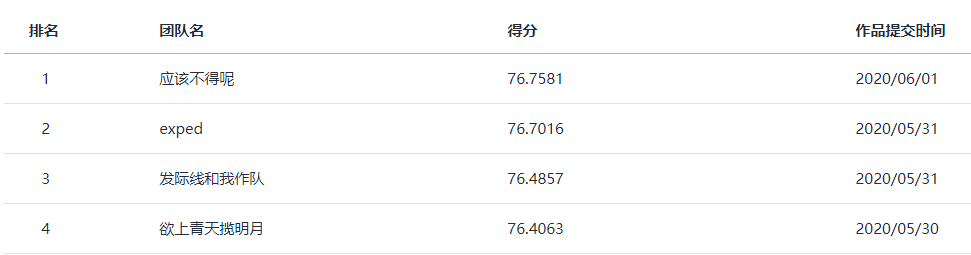
赞一个,好厉害呀
方便能认识一下你吗?看你做的项目都好厉害,求给个联系方式